Advanced Usage
Refinement and Iteration
To ensure your AI Function performs optimally and meets your specific requirements, the AI Function Builder provides a range of features for refinement and debugging. This allows you to tweak various aspects of your function beyond the initial setup.
Configurations
You can access and edit your function's configurations in the Settings page of the AI Function Builder interface:
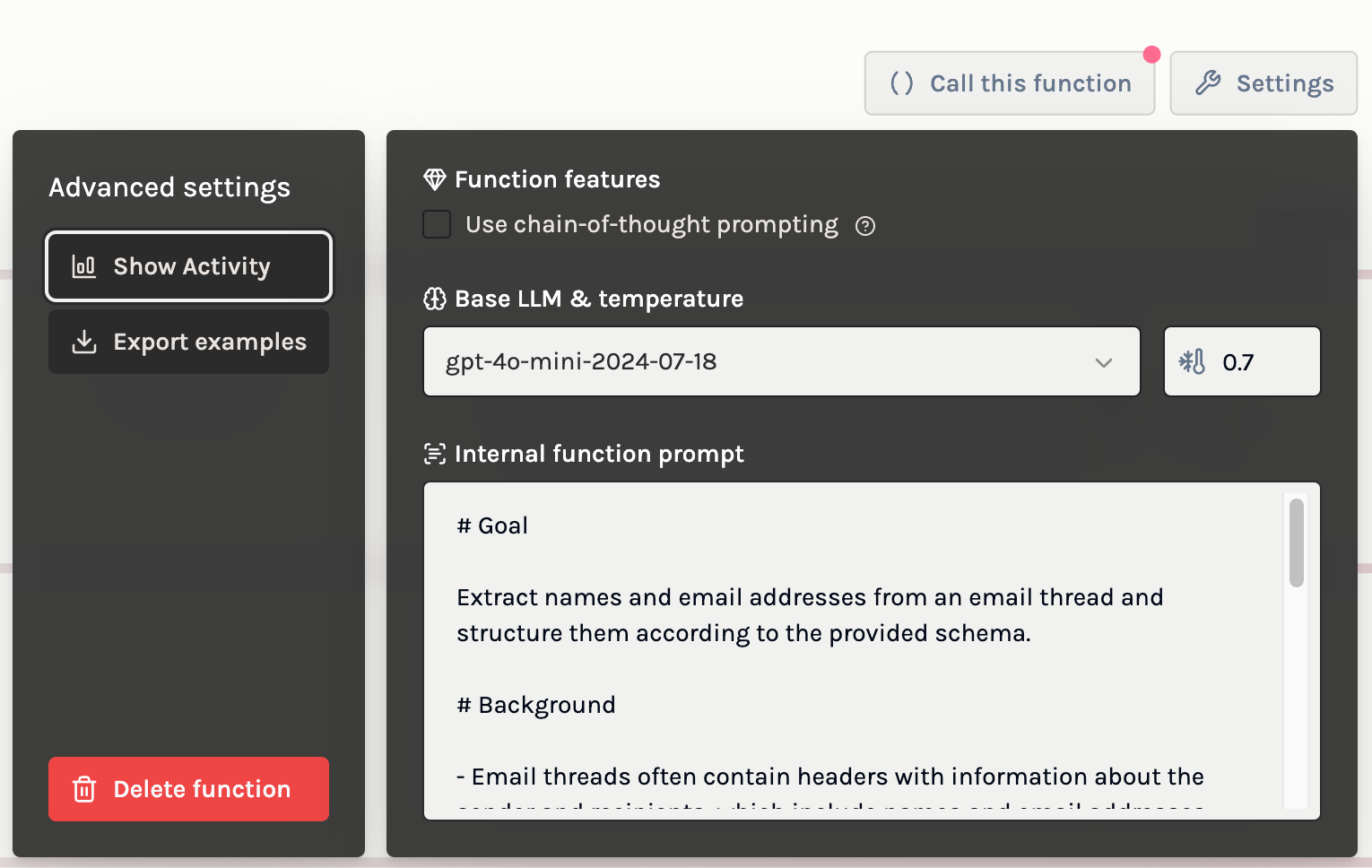
The configurations are divided into several key areas:
Base LLM
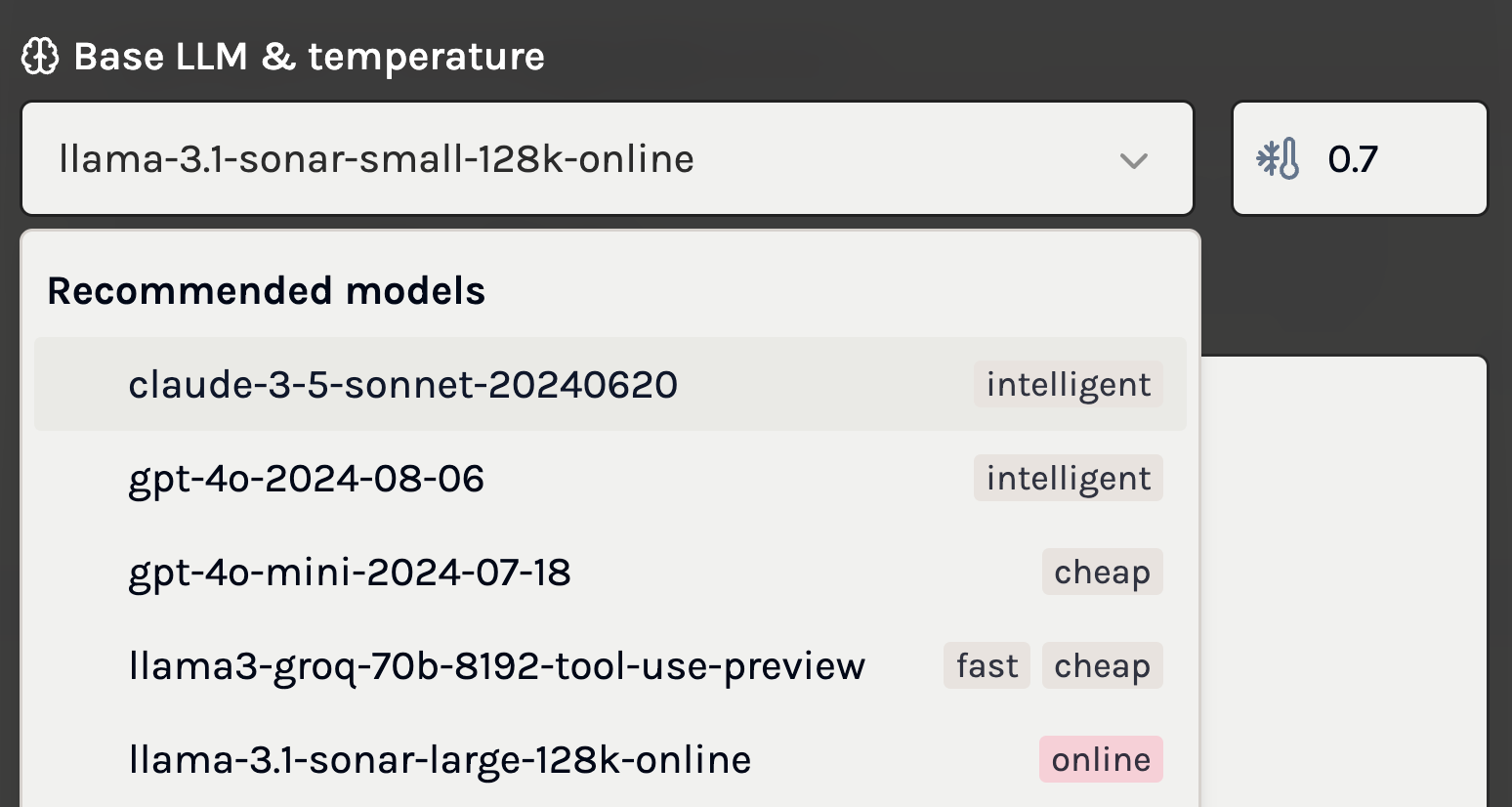
This setting allows you to choose the Large Language Model (LLM) that your function will use.
- Default Selection: The AI agent recommends a model based on your task description, aiming for a balance between performance and cost.
- Customization:
- Model Selection: You may have specific preferences regarding cost, efficiency, latency, or additional capabilities. You can select a different model from the list of supported LLMs that better aligns with your needs.
- Tags and Attributes:
- Cost: Models vary in usage fees; selecting a less expensive model can reduce operational costs.
- Latency: Some models offer faster response times, which is crucial for real-time applications.
- Intelligence: More advanced models may provide better understanding and reasoning abilities.
- Online: Certain models has the ability to get access to the internet
Example: If your application requires quick responses and operates on a tight budget, you might choose a model optimized for cost-effectiveness over a more advanced but slower and expensive model.
Internal Function Prompt
This is the set of instructions sent directly to the LLM to guide its behavior in generating outputs.
- Editing the Prompt:
- Fine-Grained Control: By editing the internal prompt, you can precisely tailor how the LLM interprets inputs and produces outputs.
- Customization: Modify the language, add specific instructions, or emphasize certain aspects of the task to improve performance.
- When to Use:
- Advanced Optimization: If you require more control than what is offered by simply editing the task description, adjusting the internal prompt can lead to better results.
- Debugging: If the function isn't performing as expected, refining the prompt can address misunderstandings or misinterpretations by the LLM.
Note: While editing the internal prompt provides more control, it requires a good understanding of how prompts influence LLM behavior.
Other Configurations
Chain-of-Thought (CoT)
Chain-of-Thought prompting enables the LLM to perform step-by-step reasoning before arriving at a final answer.
- Benefits:
- Enhanced Reasoning: Improves performance on tasks that require complex reasoning or multi-step problem-solving.
- Insight into Processing: Provides visibility into the model's reasoning process, which can be useful for debugging or understanding how conclusions are reached.
- Considerations:
- Increased Cost: Enabling CoT may increase the number of tokens used, leading to higher costs.
- Latency Impact: The additional processing can result in slower response times.
- Usage:
- Enable CoT for tasks that involve logical deductions, mathematical computations, or any scenario where reasoning steps are valuable.
Example: For a function that needs to solve complex math problems or analyze intricate data patterns, enabling Chain-of-Thought can enhance accuracy.
Temperature
The temperature setting controls the randomness of the LLM's output, affecting the creativity and diversity of responses.
- Values:
- Temperature = 0:
- The model produces the most probable response.
- Outputs in most cases should be consistent across runs with the same input, with online models being an exception.
- Temperature > 0:
- Introduces randomness into the output.
- Higher temperatures result in more diverse and potentially novel responses.
- Temperature = 0:
- Considerations:
- Lower Temperatures:
- Use for tasks requiring precise and consistent outputs, for example, classification or information extraction.
- Reduces variability, which is beneficial for predictable results.
- Higher Temperatures:
- Use for creative tasks where variety is desired.
- May produce less predictable outputs, which can be valuable for brainstorming or content generation.
- Lower Temperatures:
Editing Json Schema in Text Mode
While the AI Function Builder provides a visual interface for editing the output schema, you may prefer to edit the JSON Schema directly in text mode. When doing so, there are important considerations to ensure compatibility with the platform:
- Root Object Requirement: Incorrect Example:
- The root of the JSON Schema must always be of type
"object". If you want the output of the function to be an array, you need to encapsulate it within an object by giving it a key, such as"list".
- The root of the JSON Schema must always be of type
Incorrect Example:
Correct Example:
No Support for Definitions or Recursive Schemas:
- The AI Function Builder currently does not support advanced JSON Schema features such as
$refdefinitions or recursive schemas. - Avoid using
$refto reference definitions elsewhere in the schema. - Keep the Schema Self-Contained: Ensure all definitions are included directly within the properties without external references.
- Schema Constraints Inherit from OpenAI:
- The platform supports a subset of JSON Schema, besides constraints listed above we also inherit constraints outlined in OpenAI's supported schemas.
Version Control
Effective version control is essential for managing changes to your AI Functions over time. The AI Function Builder provides built-in version control features that allow you to track, manage, and deploy different versions of your functions seamlessly.
Automatic Versioning
- Version Creation: Each time you edit the configuration or the output schema of a function, the AI Function Builder automatically creates a new version. This ensures that all changes are tracked and previous versions are preserved.
- Version Naming:
- Default Names: Versions are named incrementally starting from
v0,v1,v2, and so on. - Consistency: This consistent naming convention helps in keeping track of the progression of your function's development.
- Default Names: Versions are named incrementally starting from
Deployed Version
- Default Deployment: The "deployed" version of your function is, by default, the latest version you have created. This means any changes you make will be reflected in the deployed function unless you specify otherwise.
- Specifying Versions:
- API and Python Client: You can specify which version of the function you want to use when querying it through the API or the Python client.
Renaming Versions

You can click the function name in the playground to edit it to more descriptive names that reflect the changes or features of that version. This is helpful for identification and collaboration purposes.
- Naming Constraints: When renaming versions, avoid using names that follow the
v+digitspattern (e.g.,v3,v4) to prevent collision with the automatically generated version names.
Managing Versions
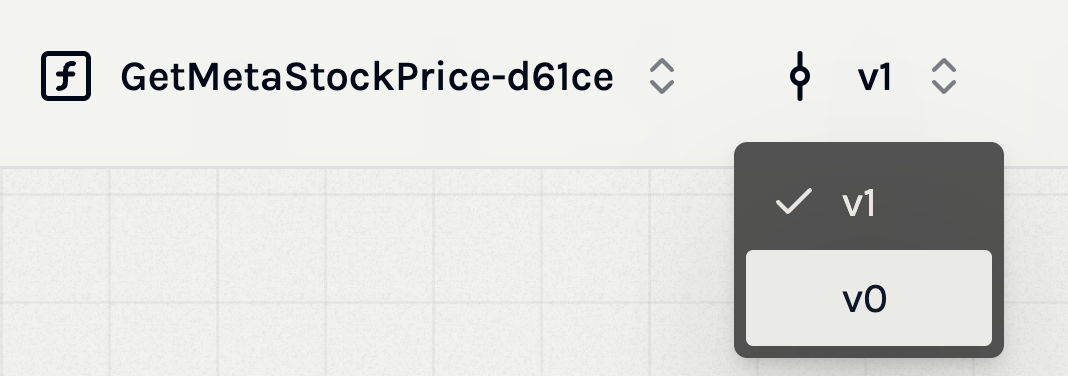
- Version History: The AI Function Builder maintains a history of all versions, allowing you to view and compare changes between them.
- Check Previous Versions: You can view the information of previous versions by switching on the top menu bar. This can also help you to check more information about
A/B Testing
A/B testing is a powerful feature that allows you to compare different versions of your AI Function to determine which one performs better. This iterative testing process helps in optimizing your function for quality, efficiency, and user satisfaction.
Comparing Function Versions
- Head-to-Head Comparison: You can compare outputs from different versions of your function side by side in the playground. This visual comparison makes it easier to assess differences in performance, accuracy, and output quality.
- Testing Scenarios:
- New vs. Old Configurations: Test how changes in configurations, such as enabling Chain-of-Thought or adjusting the temperature, affect the output.
- Model Variations: Compare the performance of different LLMs on the same task.
- Prompt Adjustments: Evaluate the impact of prompt refinements on the function's responses.

Using the Playground for A/B Testing
- Accessing the Playground: Navigate to the playground within the AI Function Builder interface.
- Selecting Versions:
- Version Selection: Choose the versions of the function you wish to compare from a dropdown menu or selection panel.
- Input Data:
- Consistent Inputs: Use the same input data for both versions to ensure a fair comparison.
- Input Options: You can input your own test data or use synthetic inputs generated by the platform.
- Viewing Results:
- Side-by-Side Outputs: The outputs from each version will be displayed side by side for easy comparison.
- Analysis: Analyze differences in content, format, response time, and adherence to the output schema.
Monitoring and Observability
Effective monitoring and observability are crucial for understanding how your AI Functions perform in real-world scenarios. The AI Function Builder provides comprehensive tools to help you track usage, analyze performance, and maintain the reliability of your functions.
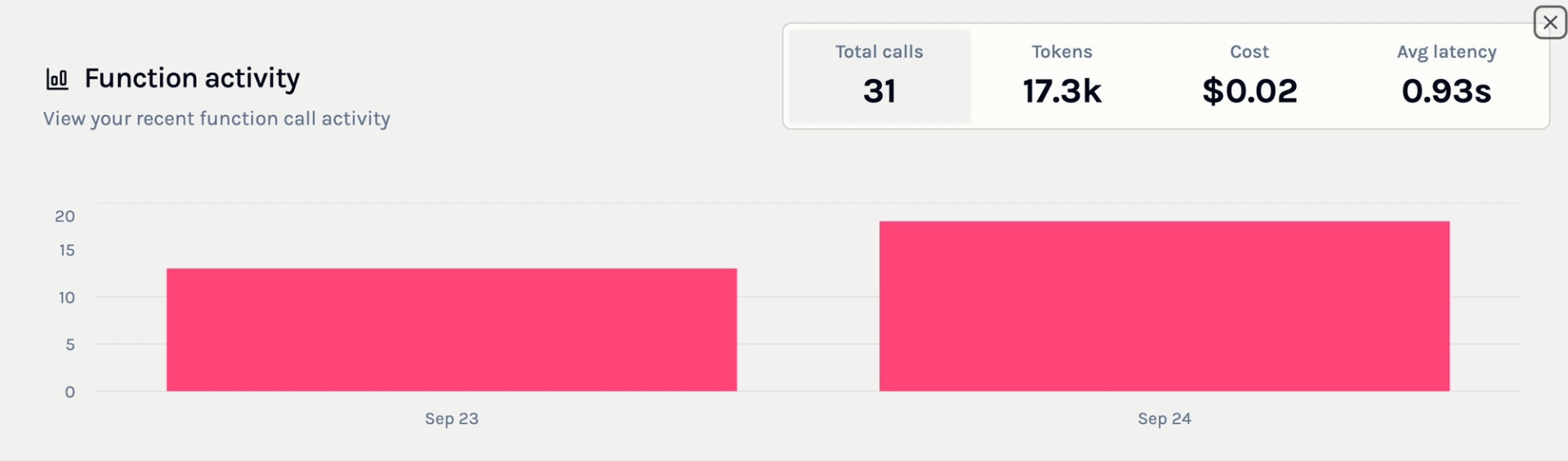
To access monitoring and observability features, click on the "Show Activity" button in the setting page:
Observability Features
The AI Function Builder automatically logs all input and output pairs for your functions. This logging facilitates observability by allowing you to:
- Review Historical Data: Examine past inputs and outputs to understand how your function is being used and to identify any anomalies or unexpected behavior.
- Debugging: Analyze specific instances where the function may not have performed as expected, aiding in troubleshooting and refinement.
- Quality Assurance: Ensure that the function consistently produces accurate and reliable outputs across different inputs and over time.
Aggregated Statistics
The Activity panel displays key aggregated statistics to help you monitor your function's performance at a glance. These metrics include:
- Number of Calls: The total number of times the function has been invoked within a specified time frame. This helps you understand usage patterns and peak periods.
- Number of Tokens: The total number of input/output tokens processed by the LLM across all calls. Monitoring token usage is important for cost management, as many LLM providers charge based on the number of tokens processed.
- Cost Over Time: Visualizations or summaries of the costs incurred over time, allowing you to track spending and budget accordingly.
- Latency: The response times for your function, indicating how long it takes to process inputs and generate outputs. Monitoring latency is crucial for applications where timely responses are essential.